

Chegou o Claude Opus 4.6: A Anthropic elevou a barra (de novo) na programação e raciocínio
A Anthropic decidiu começar o ano chutando a porta. Eles acabaram de anunciar a atualização do seu modelo mais inteligente: o Claude Opus 4.6. E, olha, não é só uma melhoria incremental qualquer; estamos falando de um salto significativo, especialmente para quem usa IA para codar ou lidar com tarefas complexas.

O que mudou de verdade?
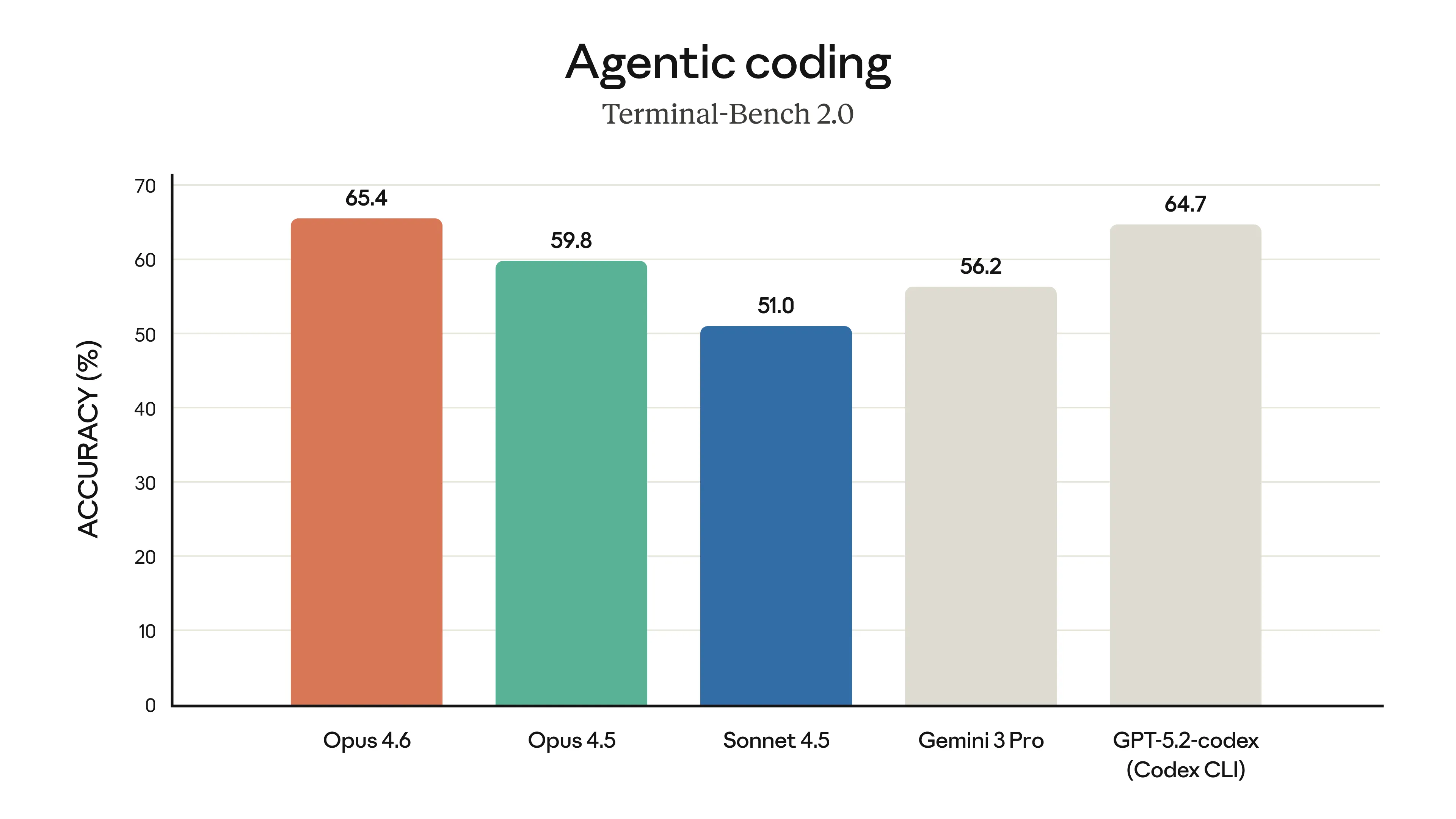
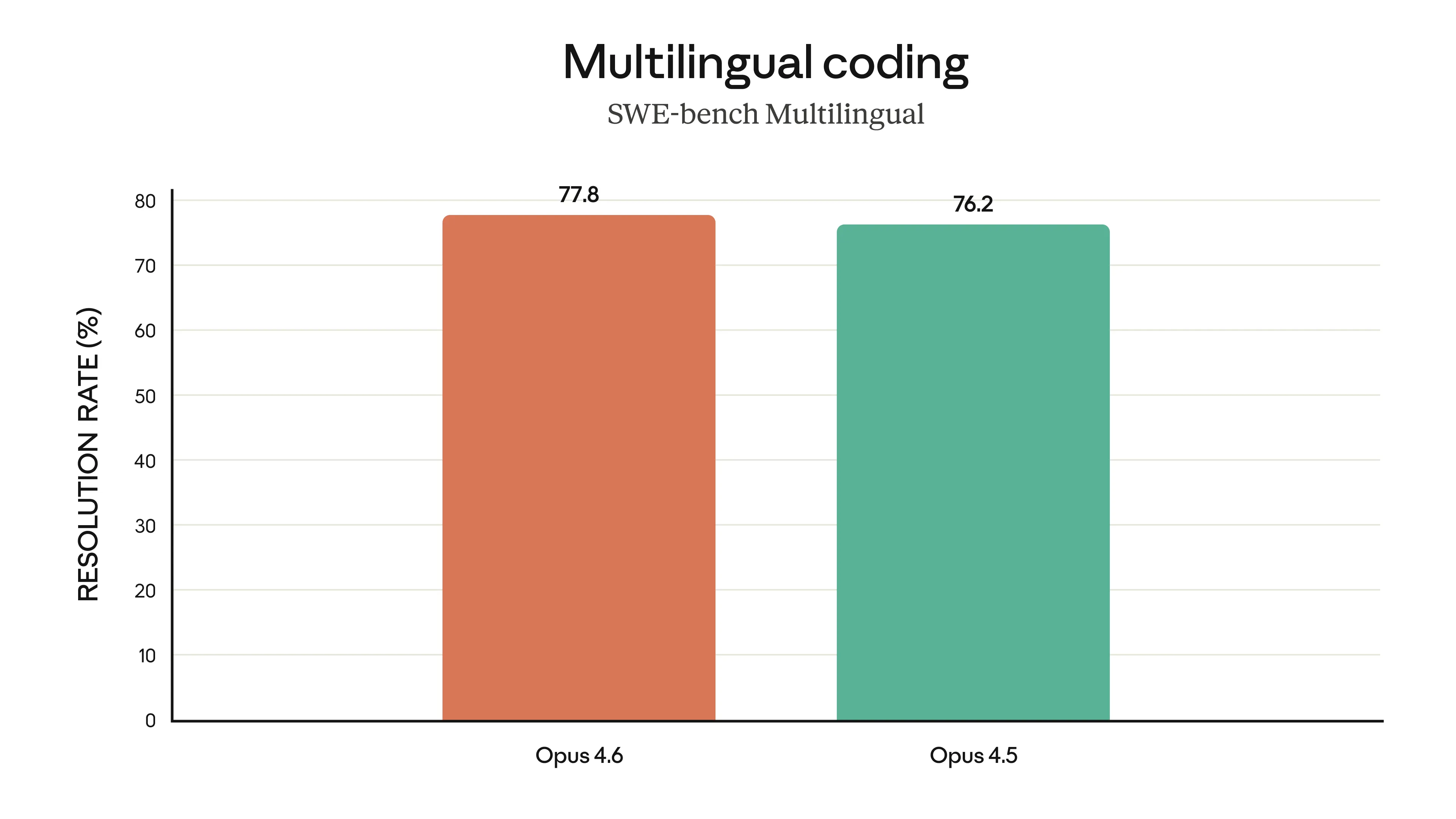
Segundo o anúncio oficial, o novo Opus 4.6 veio para resolver algumas das dores que a gente ainda sentia no dia a dia. A principal delas? Programação. O modelo agora planeja com muito mais cuidado, consegue manter tarefas agênticas (aquelas que exigem vários passos autônomos) por mais tempo e opera de forma mais confiável em bases de código gigantes.
E tem uma novidade que a gente estava esperando há tempos na classe Opus: uma janela de contexto de 1 milhão de tokens (em beta). Isso muda o jogo para quem precisa jogar livros inteiros, documentações massivas ou logs gigantescos para a IA analisar.
Desempenho nos Benchmarks
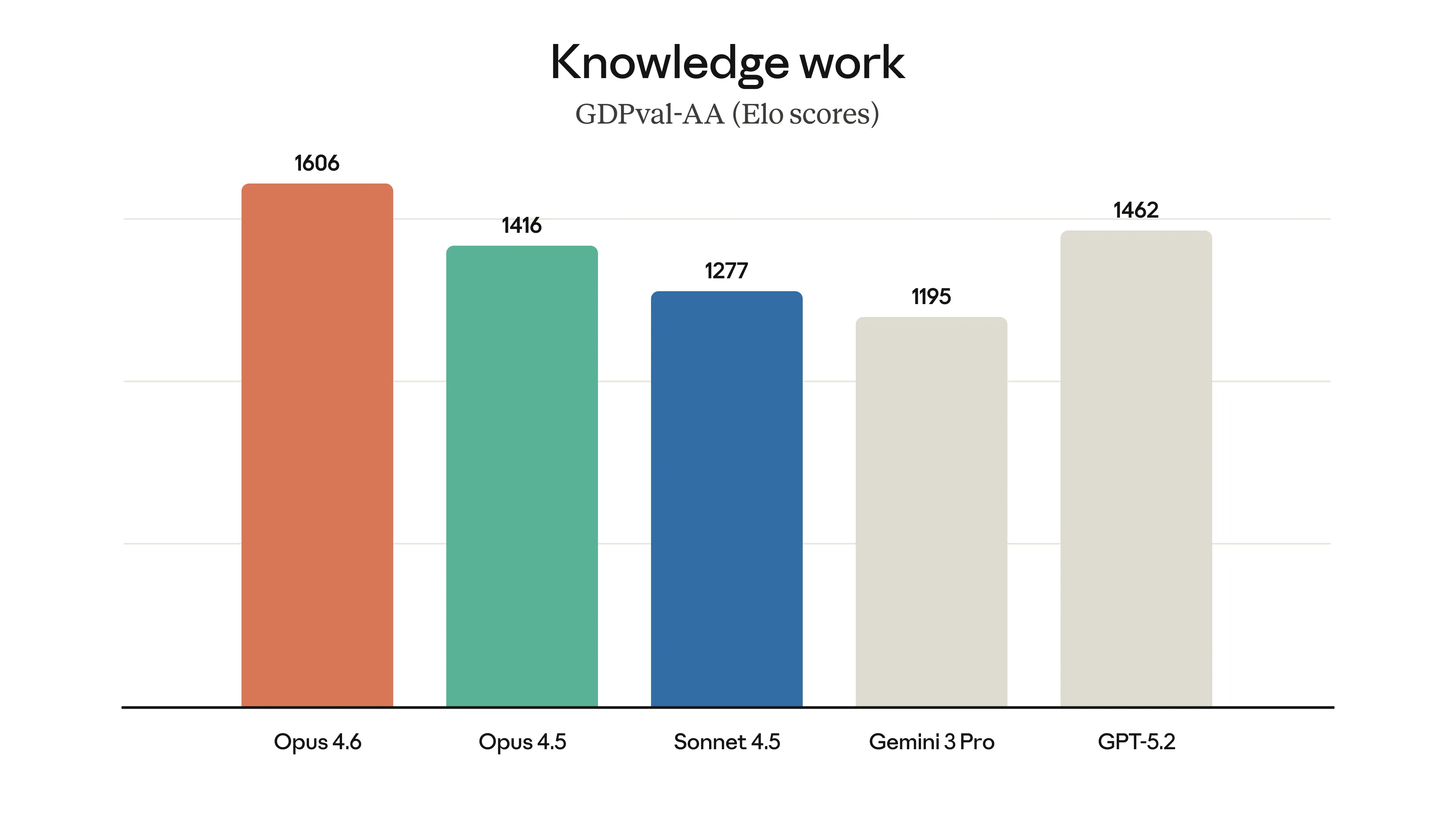
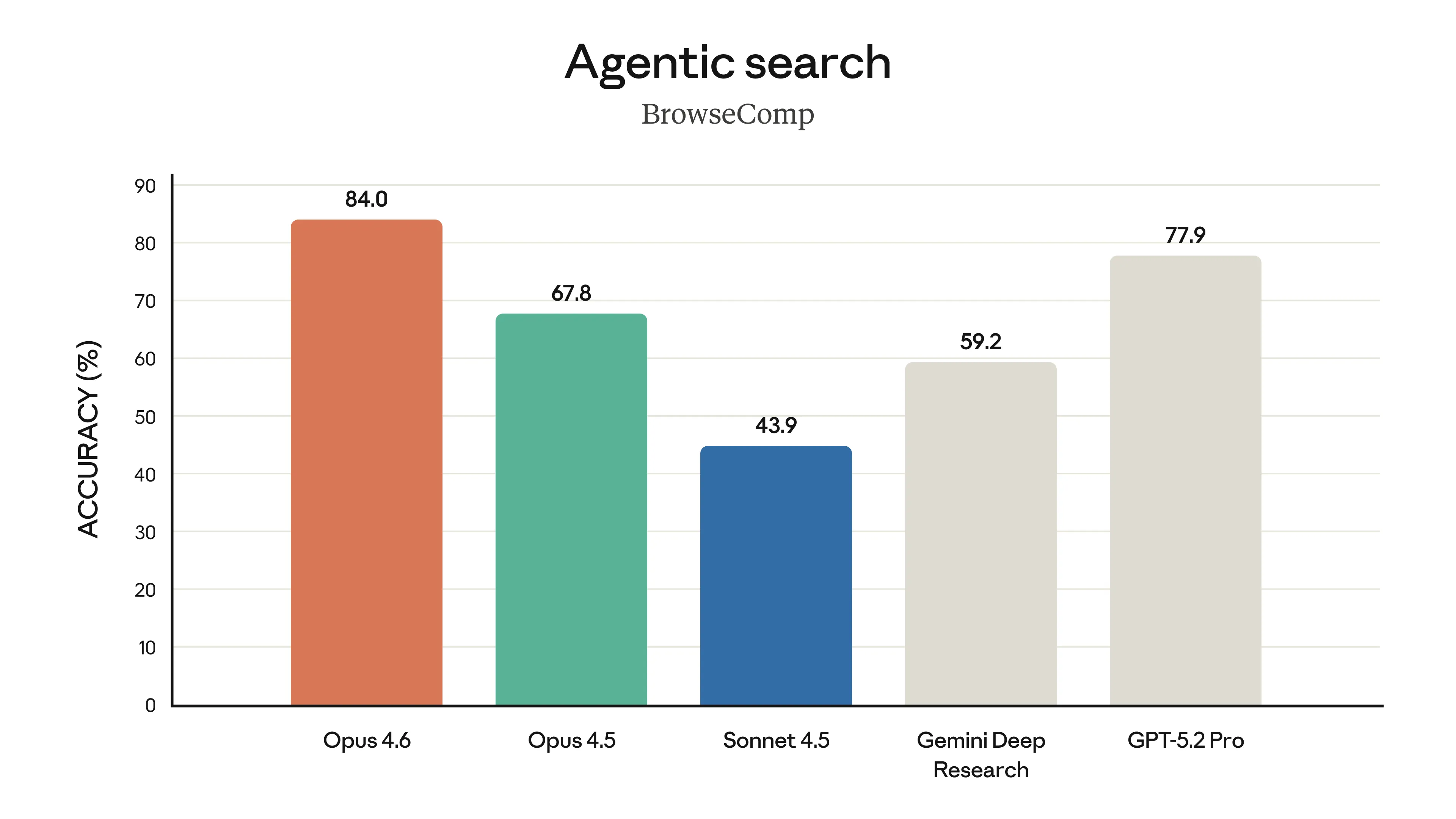
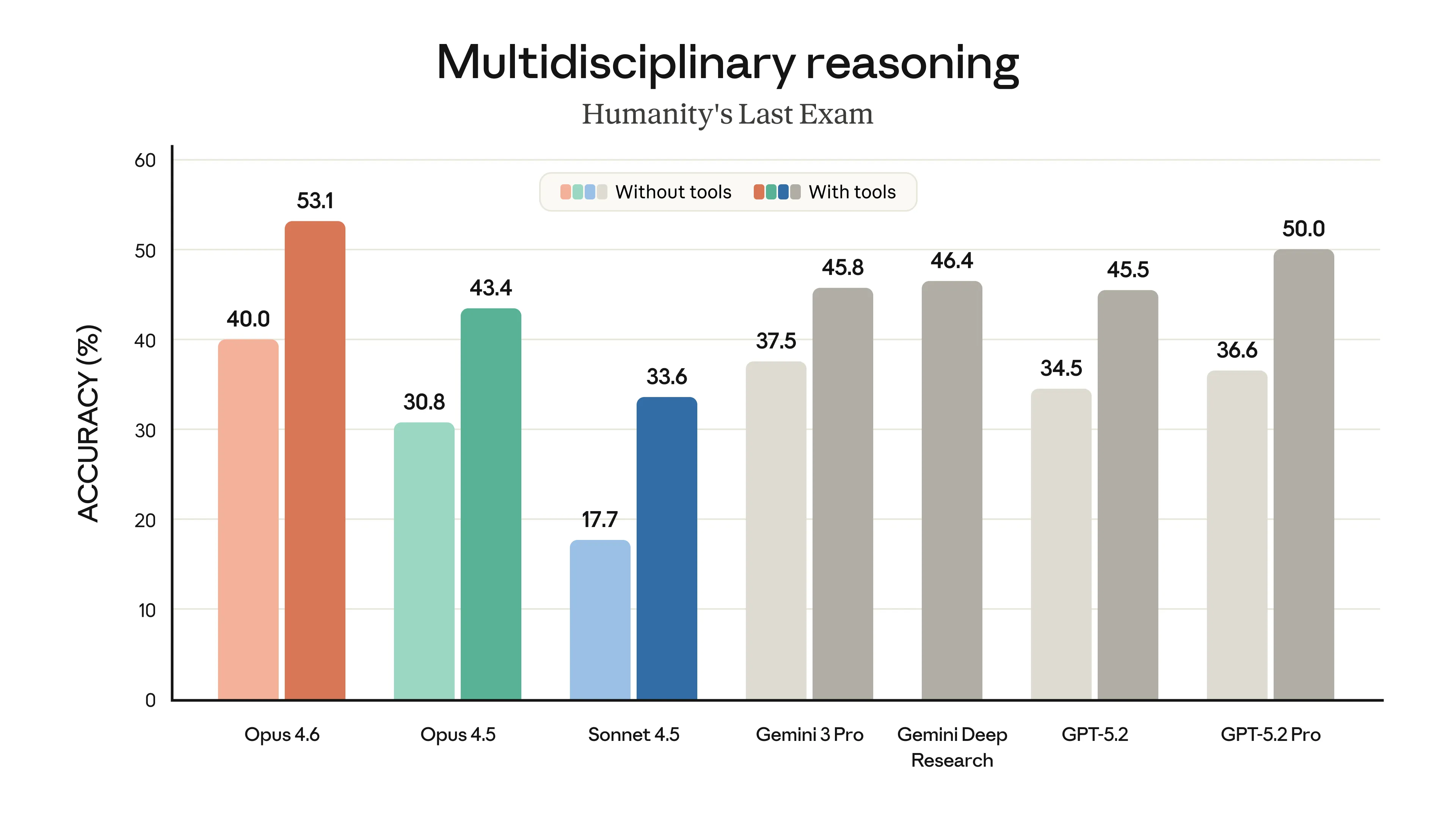
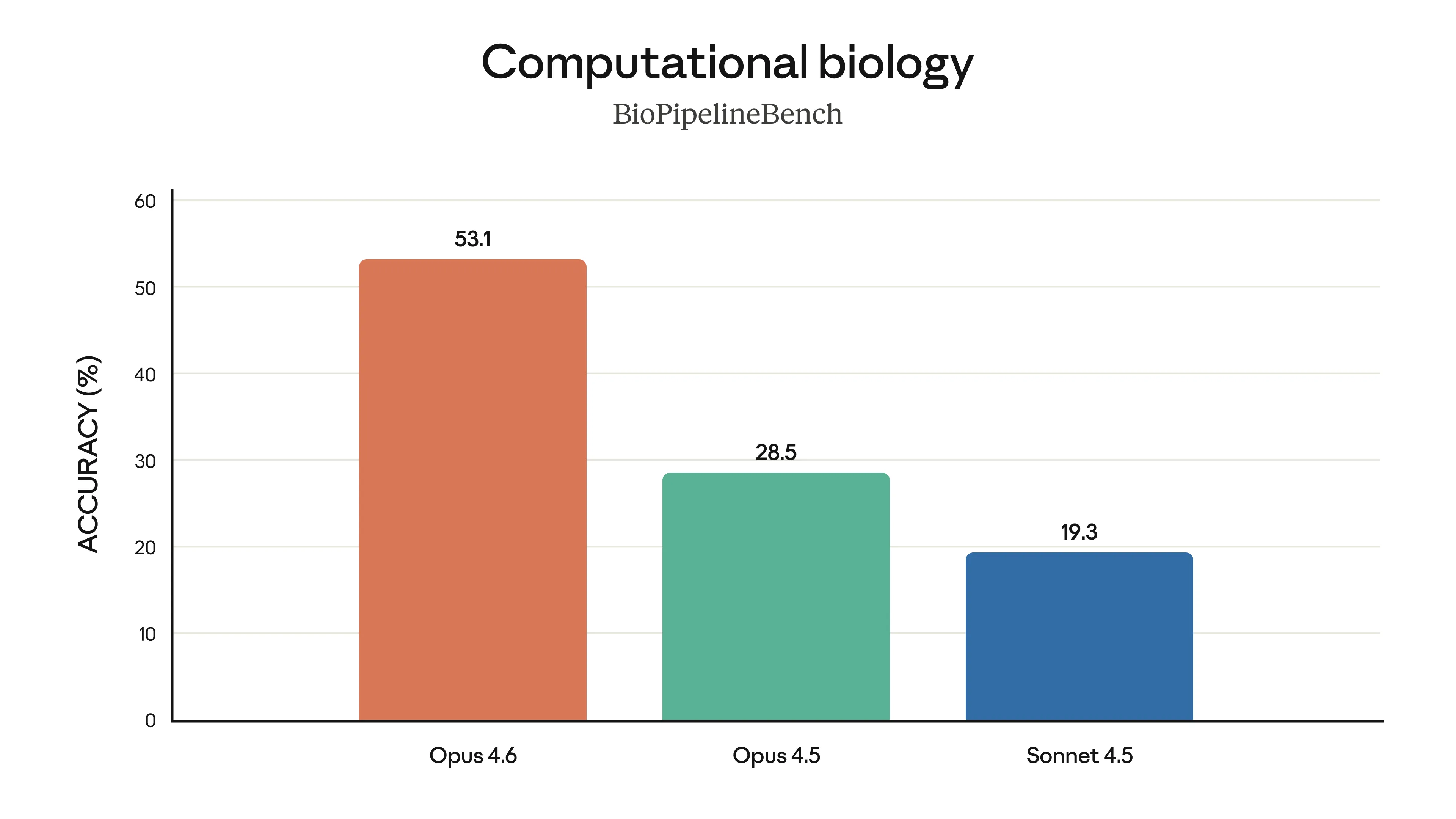
A Anthropic soltou uns gráficos que mostram o Opus 4.6 liderando em várias frentes. Ele bateu o recorde no Terminal-Bench 2.0 (focado em codificação agêntica) e está na frente de outros modelos de fronteira no Humanity’s Last Exam, um teste de raciocínio multidisciplinar bem complexo.
Um dado curioso que eles trouxeram foi a comparação no GDPval-AA, uma avaliação de tarefas de trabalho econômico valioso (finanças, jurídico, etc.). O Opus 4.6 superou o “próximo melhor modelo da indústria” (citado como o GPT-5.2 da OpenAI) por cerca de 144 pontos Elo.
Novidades para Desenvolvedores e Usuários
Além do modelo em si, a Anthropic trouxe atualizações de produto que facilitam muito a nossa vida:
- Times de Agentes (Agent Teams): No Claude Code, agora dá para montar times de agentes que trabalham juntos em paralelo. Imagina um agente revisando código enquanto o outro escreve testes.
- Context Compaction: Na API, o Claude agora consegue resumir o próprio contexto antigo. Isso é genial para tarefas longas, evitando que você estoure o limite de tokens ou perca o fio da meada.
- Adaptive Thinking: O modelo agora tem inteligência para decidir, com base no contexto, se precisa “pensar mais” (extended thinking) ou se pode responder rápido.
- Claude no Excel e PowerPoint: Eles deram um upgrade no Claude para Excel e lançaram um preview para PowerPoint. A promessa é processar dados no Excel e já gerar os slides visuais no PowerPoint seguindo o padrão da marca.

Primeiras impressões
A própria equipe da Anthropic diz que usa o Claude para construir o Claude, e o feedback interno é que o Opus 4.6 traz mais foco para as partes difíceis das tarefas sem precisar ser microgerenciado. Parceiros como Notion, GitHub, Replit e Vercel já testaram e os relatos são de que o modelo realmente entrega em tarefas multi-etapas que antes faziam a IA se perder.
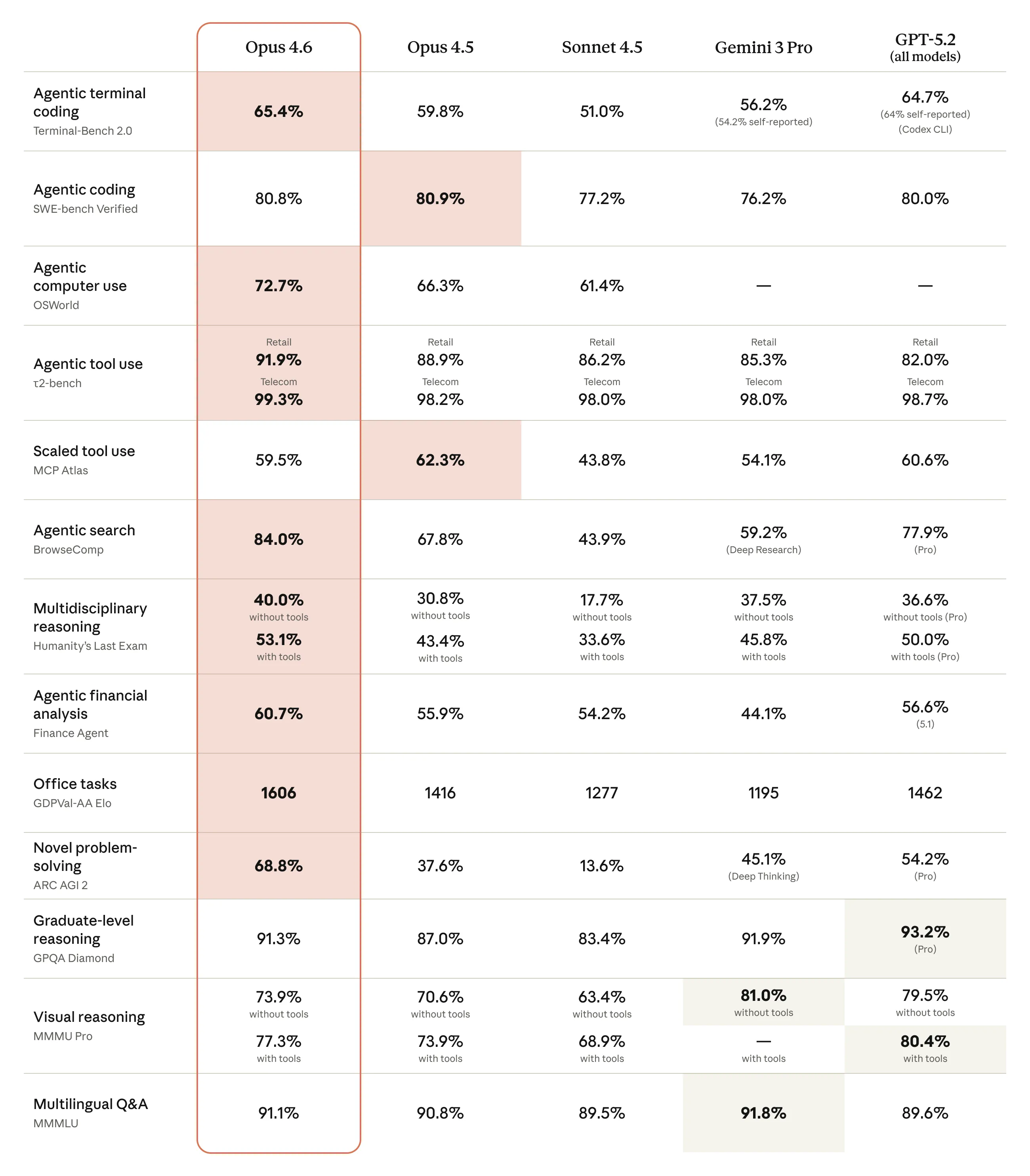
Tabela de Comparação
Para quem gosta de números brutos, segue a tabela comparativa que a empresa divulgou:
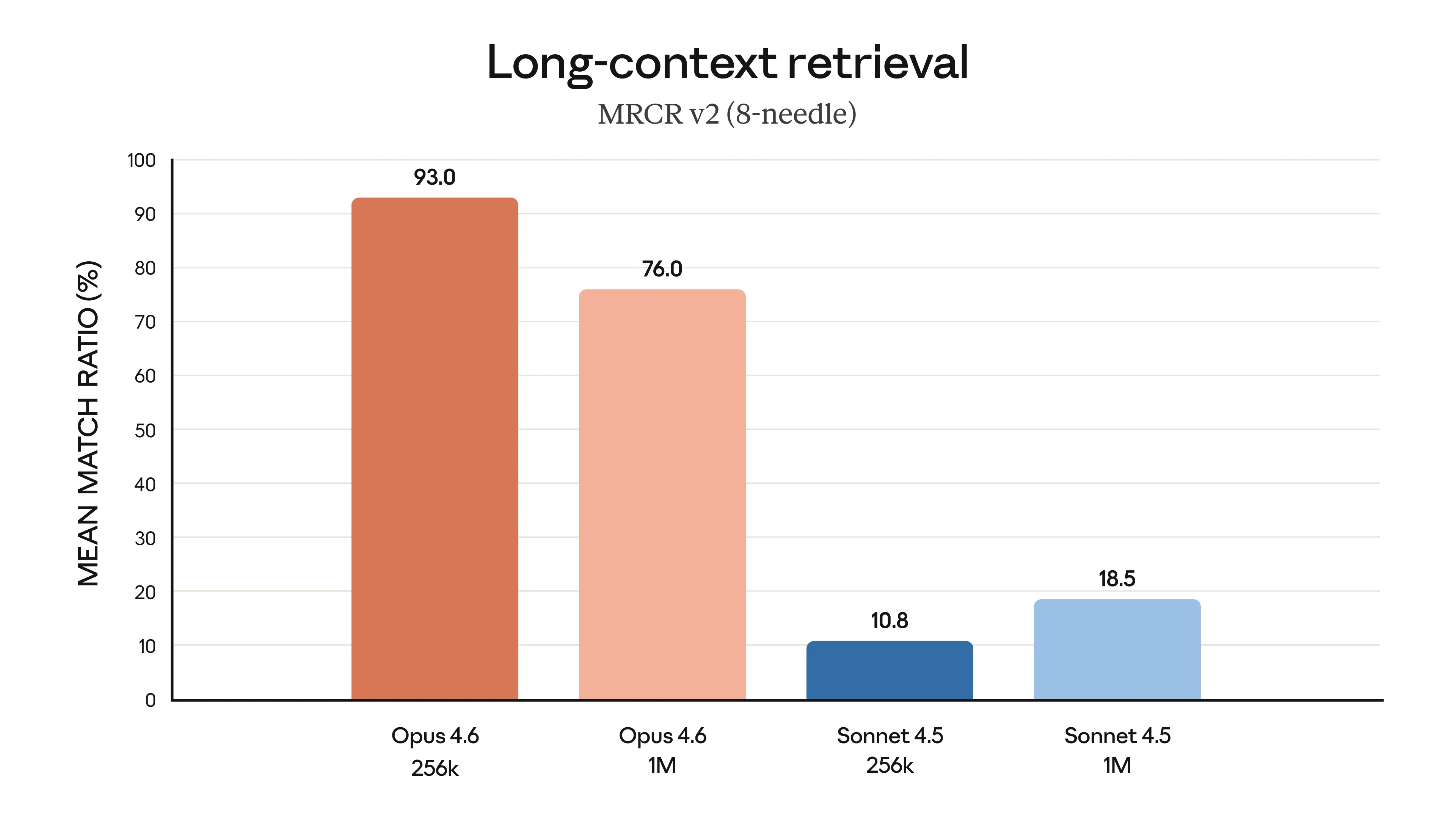
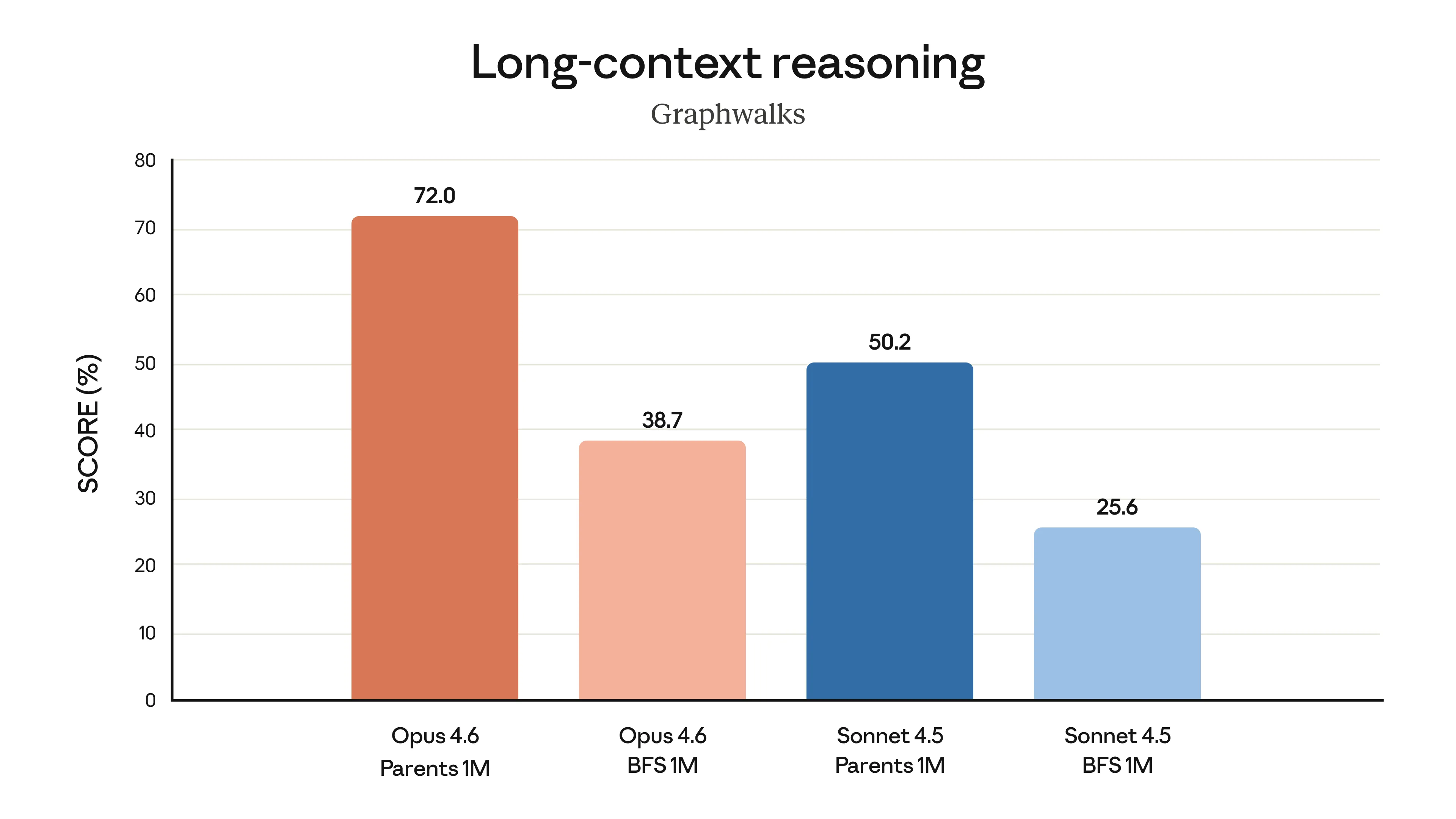
O problema do “Context Rot”
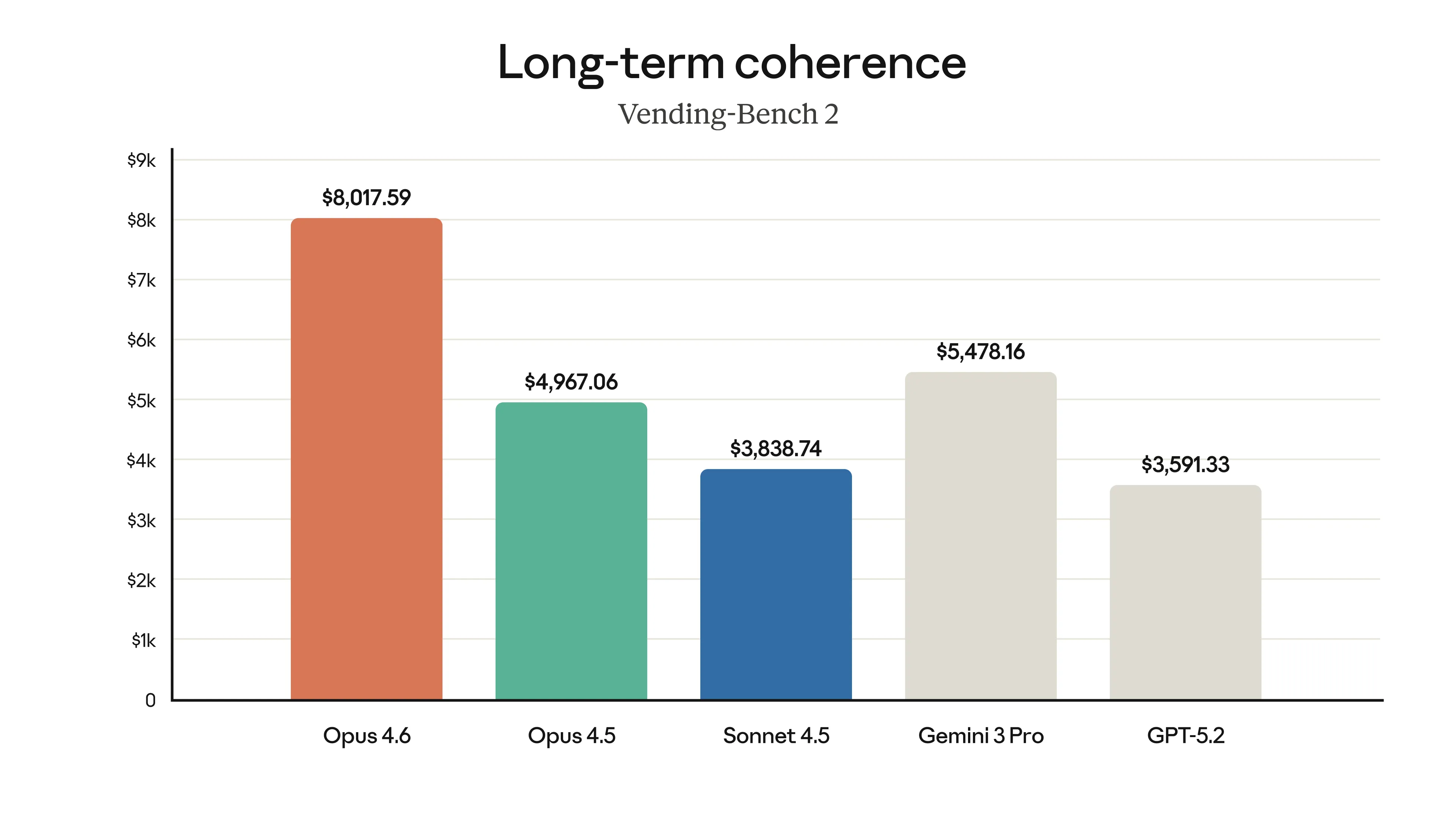
Sabe quando a conversa fica longa e a IA começa a esquecer ou alucinar detalhes do início? Isso se chama “context rot” (apodrecimento do contexto). O Opus 4.6 parece ter resolvido bem isso. Em testes de recuperação de informação em janelas de 1 milhão de tokens, ele pontuou 76%, contra apenas 18,5% do Sonnet 4.5. É uma diferença absurda na capacidade de manter a coerência em projetos grandes.
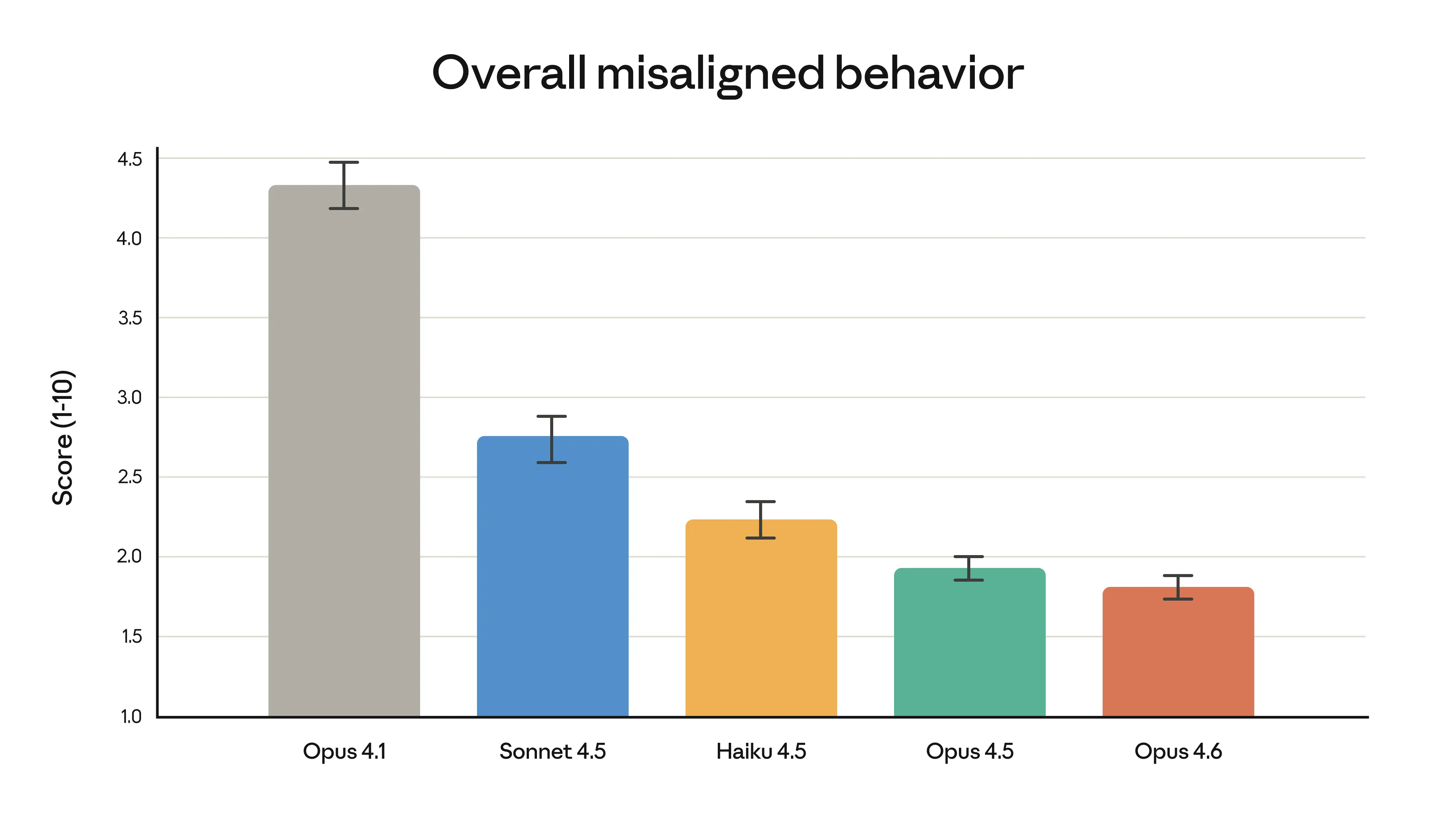
E a segurança?
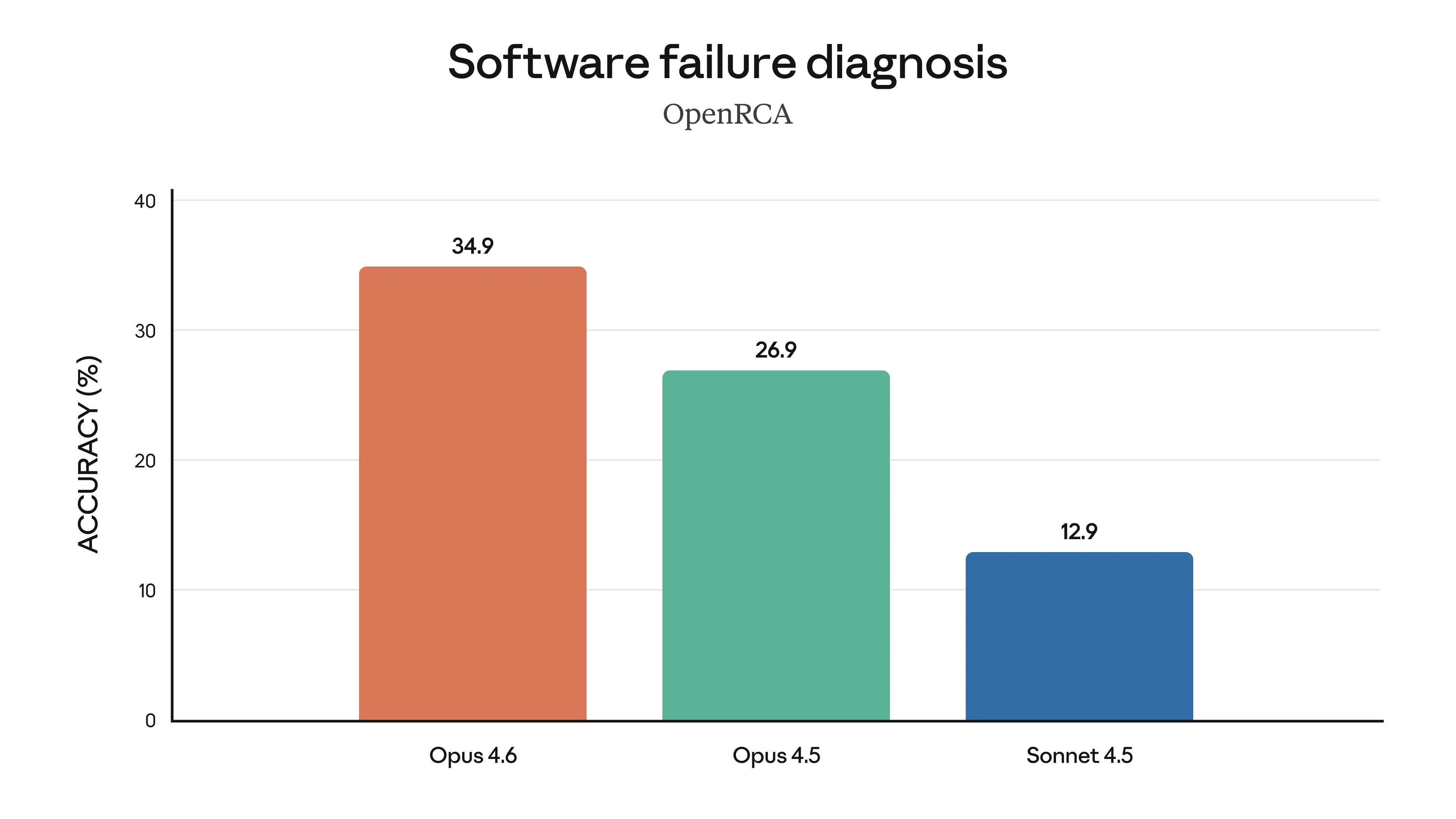
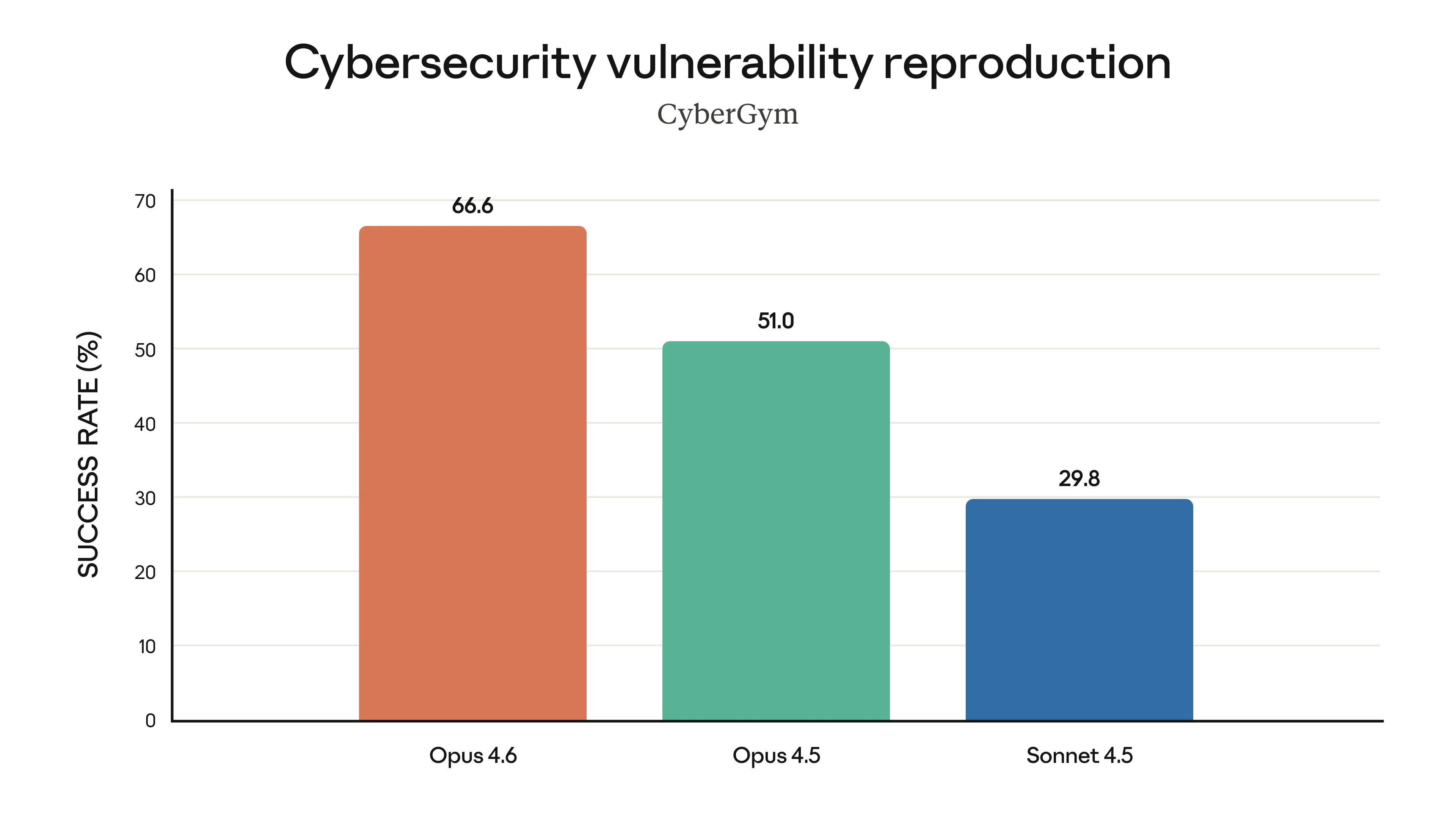
Com mais poder vem mais responsabilidade, certo? A Anthropic afirma que o Opus 4.6 mantém o perfil de segurança, com baixas taxas de comportamento desalinhado (como enganação ou bajulação do usuário). Eles até desenvolveram novos testes focados em cibersegurança, já que o modelo ficou muito bom em encontrar vulnerabilidades em códigos.
Resumo da ópera
O Claude Opus 4.6 já está disponível no claude.ai e via API. O preço continua o mesmo ($5/$25 por milhão de tokens), o que é uma ótima notícia dado o salto de performance. Se você trabalha com desenvolvimento, análise de dados ou qualquer tarefa que exige raciocínio pesado e contexto longo, vale muito a pena testar.
Links úteis

Renato Asse
Fundador da Comunidade Sem Codar
Renato Asse é fundador da Comunidade Sem Codar, a maior escola No Code e Inteligência Artificial da América Latina, com mais de 25 mil alunos formados.
Eleito o melhor professor de Bubble do mundo (#1), atua como embaixador oficial da Lovable, Bubble, FlutterFlow e WeWeb no Brasil. Pioneiro no setor, criou o primeiro canal de No Code no Youtube no país, alcançando mensalmente mais de 1 milhão de pessoas.
Materiais Gratuitos
Gestor de IA (R$12k/mês)
Descubra como faturar R$12 mil/mês criando Agentes IA sem programar. O mercado está desesperado por este profissional.
IA para Empresas
Dobre o faturamento da sua empresa com 6 Agentes de IA. Implemente hoje mesmo e saia na frente da concorrência.
Curso Gratuito de n8n
Automatize tarefas chatas e ganhe liberdade. Curso prático de n8n para iniciantes: do zero à sua primeira automação.
Acelere sua Carreira

Comunidade Sem Codar
A maior escola de No-Code e IA da América Latina. Crie aplicativos e agentes de IA profissionais e transforme ideias em negócios digitais lucrativos.
TECH 12K
Sua carreira à prova de futuro. Transforme seu conhecimento técnico em uma profissão de alta demanda e fature até R$12k/mês como Gestor de IA.
SAAS 7D
O mapa para o milhão. Domine o marketing para SaaS e MicroSaaS e escale seu negócio para 7 dígitos de faturamento com estratégias validadas.